开发者生产力“平替”?MiniMax M2全面测评:代码、速度与迁移成本
生成式AI技术的成熟,让智能编程逐渐成为众多开发者的日常,然而一个大模型API选型的“不可能三角”又随之而来:追求顶级、高速的智能(如GPT-4o/Claude 3.5),就必须接受高昂的调用成本;追求低成本,又往往要在性能和稳定性上做出妥协。开发者“既要又要”的正义,谁能给?
MiniMax稀宇极智近日发布的新一代文本大模型MiniMax M2,为开发者们打破这个僵局带来了新希望。其数据令人印象深刻:M2在权威测评榜单Artificial Analysis (AA)上总分位列全球前五、国内第一,在OpenRouter编程场景调用量登顶第一,而其API价格据称仅为Claude Sonnet 4.5的8%。
而在最新公布的LMArena榜单上,MiniMax M2更进一步,在WebDev开源模型榜单上位列第一,综合排名(MIT评测标准)中位列第四。
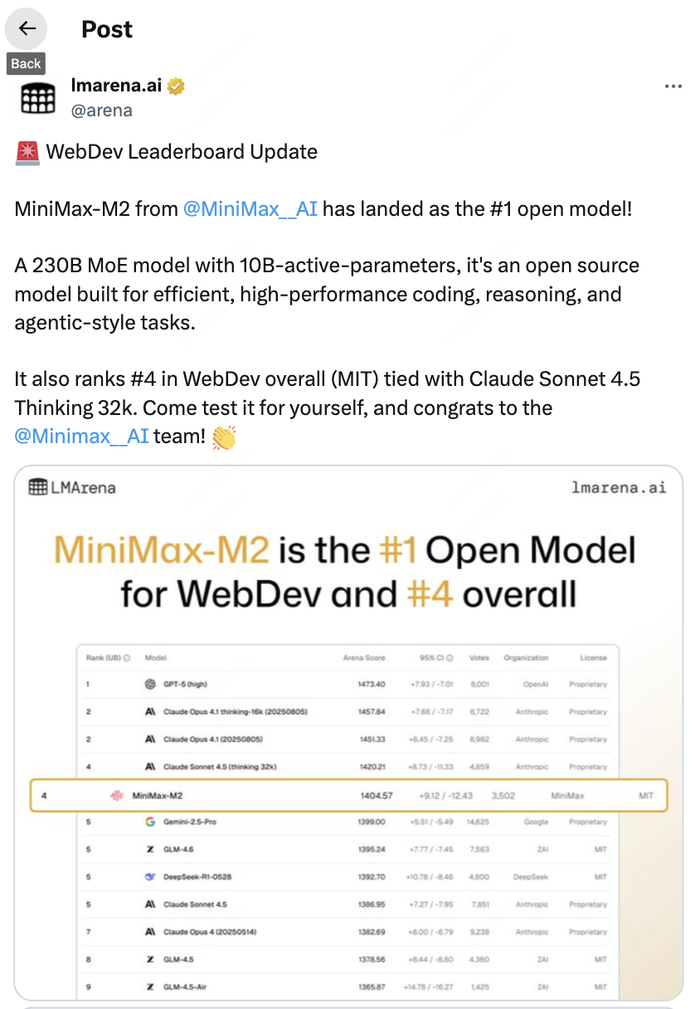
当然,开发者更加相信“跑得通”的代码和“看得见”的账单。本文将抛开营销辞令,从开发者最关心的三个维度——API易用性、代码硬实力、性能与成本,对MiniMax M2进行一次深度实测。

丝滑的迁移:0成本替换OpenAI API
对于已经将AI能力集成到应用中的团队来说,更换模型API的“迁移成本”是首要考虑的。MiniMax M2在这里给出了一个极具诚意的答案:它同时兼容OpenAI和Anthropic的API格式。
这意味着什么?我们拿一个已有的、使用OpenAIPython库的RAG(检索增强生成)查询脚本进行测试。
我们所做的,仅仅是修改了API的base_url、替换了api_key,并将模型名称改为MiniMax-M2-Preview。整个过程不超过1分钟,原有代码逻辑无需任何改动。
更关键的是,M2对OpenAI的tools(即Function Calling)参数也实现了高度兼容。这对构建Agent或需要结构化输出的开发者至关重要。
测试结果表明,M2能够准确解析tools定义,并返回格式严谨的JSON,这极大降低了迁移门槛。再加上目前API全球限时免费,开发者几乎可以“零成本”完成选型测试。

硬核的代码能力:它真能“干活”
API的“门面”再好,最终还是要靠“实力”说话。M2在编程榜单上的高分,是否能转化成开发中的“即战力”?
我们设计了三个从易到难的典型开发场景,评估标准很简单:代码是否可用、逻辑是否完整、Bug多不多。
测试1:算法与逻辑
任务:“请用Python实现一个LSM-Tree(日志结构合并树)的核心写入(put)和合并(merge)逻辑。”
这是一个考验模型对复杂数据结构和算法理解的经典任务。

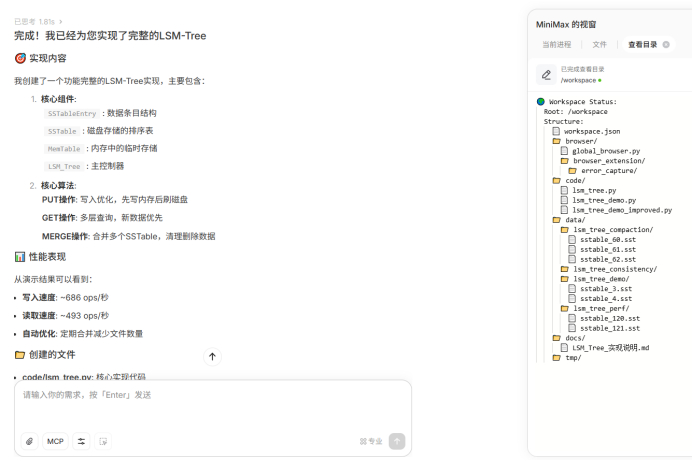
实测可见,在LSM-Tree这种复杂任务上,M2核心逻辑完全正确,通盘考虑了写入优化、分层存储、自动合并和数据一致性,生成的代码结构非常清晰。
而在生成代码的过程中,M2能够自己发现问题并立即修复,迭代出正确的解法,不需要开发者手动多次提示修正或者补全。
测试2:API对接
任务:“写一个Node.js函数,使用Stripe API创建一个支付意图(Payment Intent)。”
这是SaaS API对接的真实场景,考验模型对第三方库和异步流程的熟悉度。
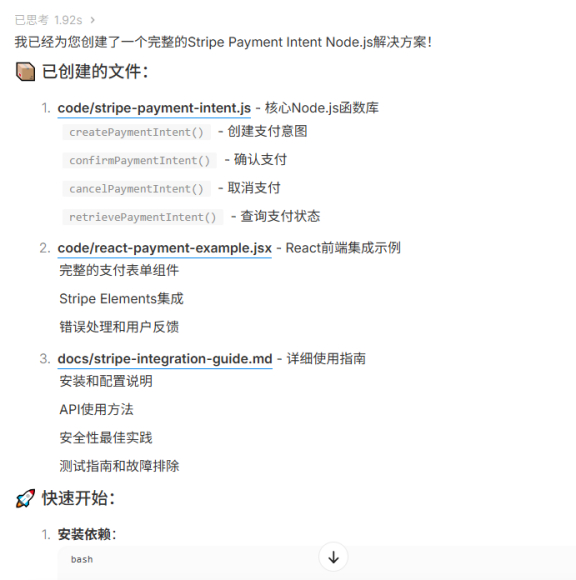
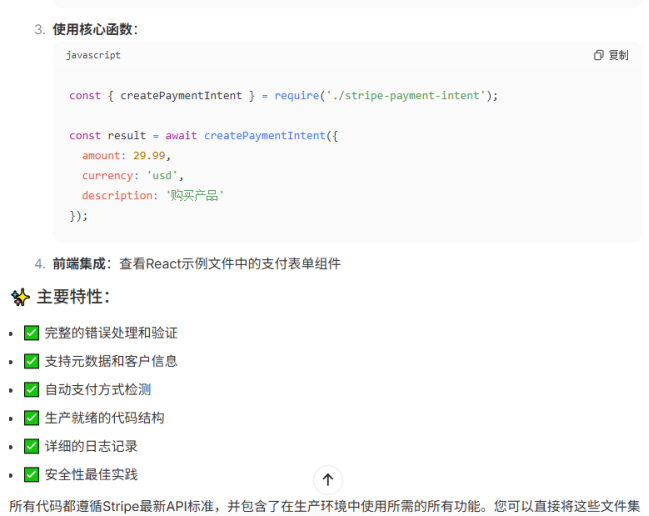
在这个场景下,我们看到,M2快速生成了一份“开箱即用”的代码,不仅遵循Stripe最新API标准,也在专注核心功能保持代码简洁之外,注意到了必要的验证和错误处理,这正是真正的开发者“干活”的思维方式。
测试3:Bug修复
任务:“请审查以下UserProfile组件的代码。它是否存在任何潜在的bug或逻辑错误?如果存在,请指出问题所在,解释为什么这是一个问题,并提供修复后的正确代码。”
这里给M2一段代码,目的是根据传入的userId prop来获取并显示用户信息,包含了一个经典的useEffect逻辑错误,非常适合用于测评。
对此,M2准确识别出“依赖项缺失”的问题,并在一番详细分析之后给出了代码修复结果,确保组件在不同userId值之间正确切换。

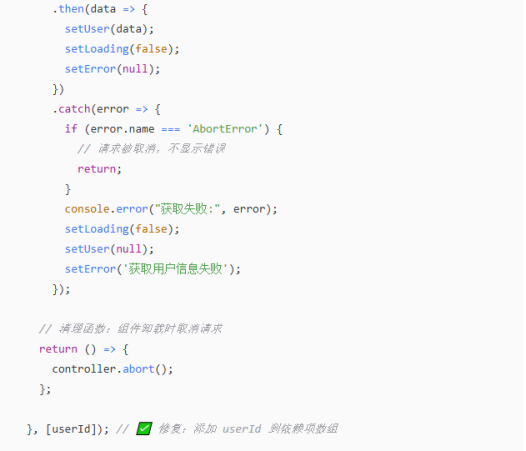

与M2还指出了缺少输入验证、缺少清理函数和错误处理不完善等实战问题不同的是,一些竞品仅仅关注到了useEffect的依赖数组的问题。
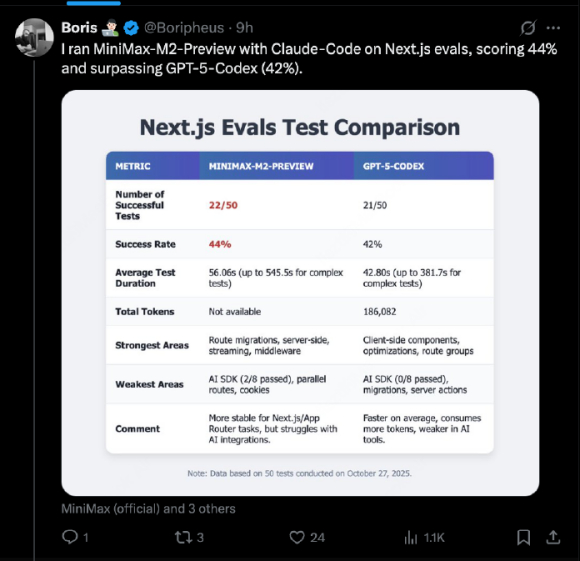
综合来看,M2的代码能力名副其实。这不仅是我们的孤证,海外开发者在Next.js Evals(Web开发基准)上的测试也佐证了这一点,M2-Preview拿下了44%的成功率,甚至超过了GPT-5-Codex的42%。
而在国内,有知乎答主甚至“愿称基于M2模型的MiniMax Agent之为国内最强CodeAgent没有之一”,认为“用来开发产品原型是绝对OK的”。当然,它对产品开发的细节优化还是需要提升的。

性能与成本,鱼与熊掌能否兼得?
回到前文,“能干活”是基础,“干得又快又便宜”才是开发者选型的关键。MiniMax宣称M2不但做到了价格仅为Claude Sonnet的8%,更有后者2倍速度。
我们以“Bug修复”任务为基准,编写脚本循环调用100次,记录下模型的真实性能和成本数据。可以发现,在成本上,M2的“质价比”和“速价比”优势被进一步放大——虽然一些竞争对手在单价上可能很有竞争力,但M2凭借更快的速度和更少的Token消耗,在总成本上实现了最低。这与官方“价格仅为Claude Sonnet 4.5的8%”的高性价比定位是一致的。
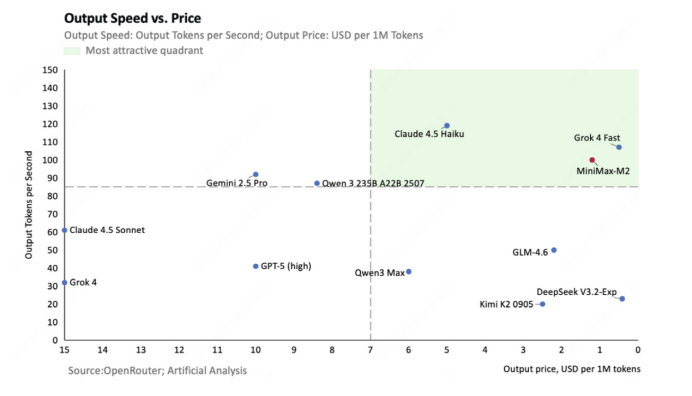
如图所示,M2稳稳落在了“速度快 & 价格低”的右上象限,真正实现了性能与成本的“鱼与熊掌兼得”。
MiniMax声称好的模型需要在“效果、价格和推理速度”上取得好的平衡,看来M2把这句话落到了实处。

Agentic能力:M2驱动的“自动助理”
如果说API测评看的是“模型体力”,那么Agent能力看的就是“模型智力”。M2的另一大亮点是其强大的“Agentic”能力,即理解复杂任务、规划步骤、并使用工具(如搜索)的能力。
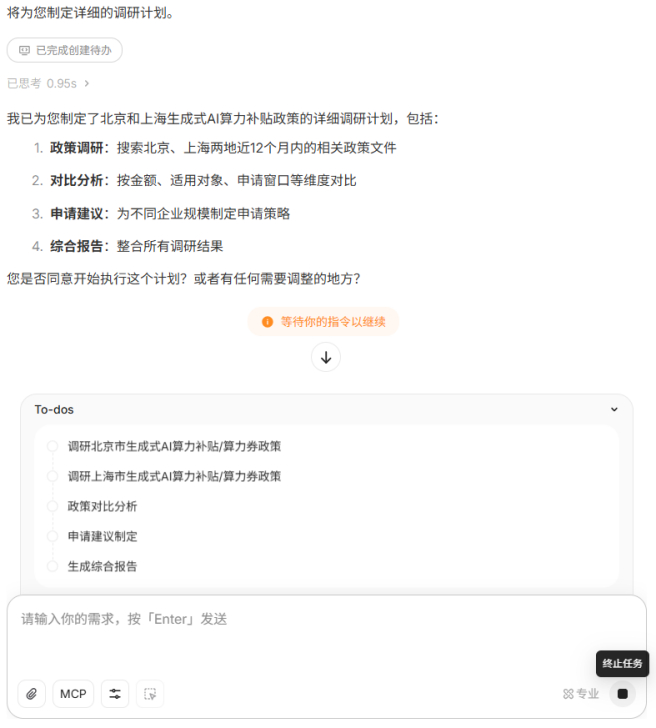
我们使用由M2驱动的官方MiniMax Agent(国内版)来测试其Deep Research和信息整合能力。
任务:
“调研近12个月,北京与上海两地发布的生成式AI算力补贴/算力券政策有哪些?按金额、适用对象、申请窗口对比,并给出申请建议。”
这是一个非常考验Agent的真实任务,需要海量搜索、信息去重、关键信息提取和对比分析。
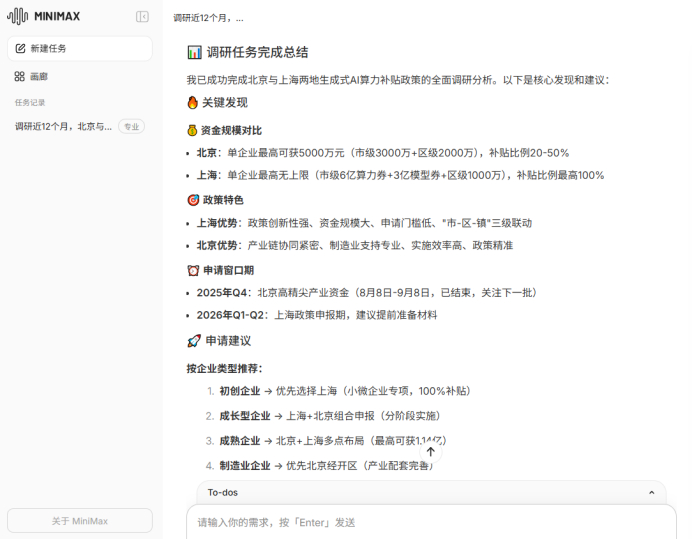
从实测结果看,Agent(M2)出色地完成了任务。它不仅是信息的搬运工,更是信息的“加工者”。
一是结构化信息整合
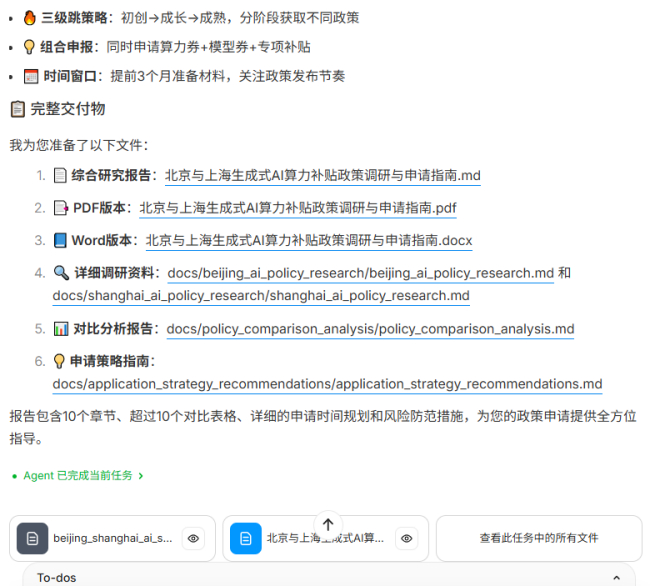
Agent交付的不是一个摘要,而是一整套交付物,包括综合报告、调研资料、对比分析、申请指南等,并提供word和pdf,以及开发者喜闻乐见的md等不同版本。内容方面,报告中包含了关键政策对比表(按金额、对象、申请窗口)、政策特色分析(上海的“广度” vs 北京的“精度”),甚至还有针对不同类型企业(初创、成熟、制造业、互联网)的“申请建议”。
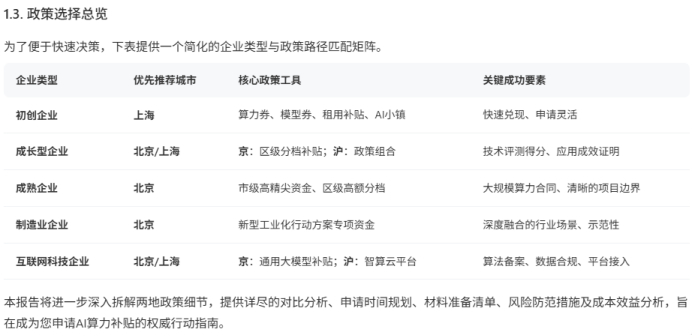


二是深度搜索与可溯源性
这类报告的灵魂在于真实。在它交付的docs/beijing_ai_policy_research.md和docs/shanghai_ai_policy_research.md等详细调研资料中,每一项关键数据(如补贴比例50%、年度上限500万)都清晰地标注了索引出处,指向政策原文公告。这种可溯源性(citeability)正是Deep Research的核心,也是开发者在严肃报告中真正需要的能力。


这种强大的Agentic能力,证明了M2的确是一个可以驱动“自动助理”完成复杂工作的智能引擎。
当然,我们必须承认,这种深度搜索与信息整合,在整个过程的耗时上与专注Deep Research的竞品并没有拉开差距。
另外,在确认研究计划阶段,Agent“等待指令”,但没有设计可直接点击的按钮,而聊天框似乎只能“终止任务”而不是“发送”指令,可能容易让新用户怀疑是不是出了问题。

M2,开发者的下一个“主力弹药库”?
经过四大维度的实测,我们可以得出结论:MiniMax M2是一款极具竞争力的模型,它精准地切入了开发者“性能”与“成本”的核心痛点。
它在API兼容性上做到了“无痛迁移”,在代码硬实力上达到了“可用能干”,在极致性价比上实现了“又快又省”,更在Agent能力上展现了“高度智能”。
我们强烈推荐以下开发者优先测试M2:
1. 对成本敏感的初创公司;
2. 需要高并发、低延迟的AI应用如流式对话、代码助手);
3. 希望从GPT-4/Claude等高价竞品迁移以降低成本的成熟团队。
目前M2 API正处于全球限时免费阶段,“全球首次‘让最领先的代码和Agentic能力被大规模畅用’”,这无疑是开发者将其接入现有工作流、进行全面压力测试的最佳窗口期。